AI in Robotics Perception and Autonomous Navigation
Exploring the concepts of AI, Visual AI, Machine Learning, and Deep Learning and the way Sevensense leverages these technologies as part of its offering beyond Visual SLAM
Request A Meeting
Please fill out your details below. Our team will reach out to you by email to schedule a date and time.
Its impact on Visual SLAM and beyond
It is clear that Artificial Intelligence (AI) is here to stay and there is a need for an open discussion, to bring some light into the AI black box.
At Sevensense Robotics we strongly believe that transparency builds trust, this is why we decided to tackle the elephant in the room and dissect the role that AI plays in our offering.
Let’s start by exploring what AI is and the difference between Machine Learning (ML) and Deep Learning (DL).
The original definition of AI, coined in 1955 by John McCarthy -one of the founding fathers of the discipline- was really broad: “The science and engineering of making intelligent machines.”
Nowadays, we conceive AI as a subset of computer science focused on creating systems that can replicate human intelligence and problem-solving abilities. It involves any technique that enables machines to mimic human intelligence, using logic, if-then rules, decision trees, and machine learning -including deep learning.
Machine Learning (ML) is a subset of AI that intersects with statistics. It involves the development of algorithms and statistical models that enable computers to learn and make predictions or decisions without being explicitly programmed; instead, they recognize patterns in the data and make predictions once new data arrives.
Deep Learning (DL) is a specialized subset of Machine Learning that analyzes data with a logical structure similar to how a human would draw conclusions.
To achieve this, DL applications use a layered structure of algorithms called an Artificial Neural Network (ANN). It is characterized by its deep layers of interconnected nodes or neurons, which allows it to automatically learn hierarchical representations of data, making it well-suited for tasks like image and speech recognition.
The three technologies are nested one within the next:
.png)
Visual AI refers to Artificial Intelligence applications that focus on enabling machines to interpret, understand, and process visual information, such as images and videos. Visual AI technologies employ advanced Machine Learning algorithms, Deep Learning models, and computer vision techniques to analyze and extract meaningful insights from visual data.
AI-Powered Robot Autonomy
Sevensense uses Visual AI to allow robots to identify, understand, and act on imagery and visual data -captured by cameras- just like humans so that they can navigate autonomously.
By processing camera images with AI, the process known as Visual Simultaneous Localization and Mapping (SLAM) builds a rich 3D map of the environment and precisely localizes within it.
Sevensense’s Visual SLAM technology comprises proprietary and lightweight AI sensor fusion algorithms to enable robots to precisely estimate their position. This is achieved by extracting distinctive elements from the images, for example, a corner of a window, and using these to build a representative yet compact 3D model of the environment.
To deliver robust and high-performing localization under all conditions, including lighting and environmental changes, Sevensense employs AI -more concretely Deep Convolutional Neural Networks- for feature extraction. Incorporating AI for this purpose makes it possible to overcome a limiting constraint of legacy SLAM technology, which until now could not cope with significant illumination and other environmental changes, leading to failures during autonomous navigation in difficult settings.
Sevensense also uses machine learning to maintain the visual maps of dynamic spaces to ensure robust localization and reusability of the initial map of the environment. The solution known as Lifelong Visual SLAM is basically a multi-session map that uses the initial map as the basis and later on, the changes in the environment are added to it to enrich it. All of this, without the need to run Visual SLAM from scratch on each session, increases operational efficiency.
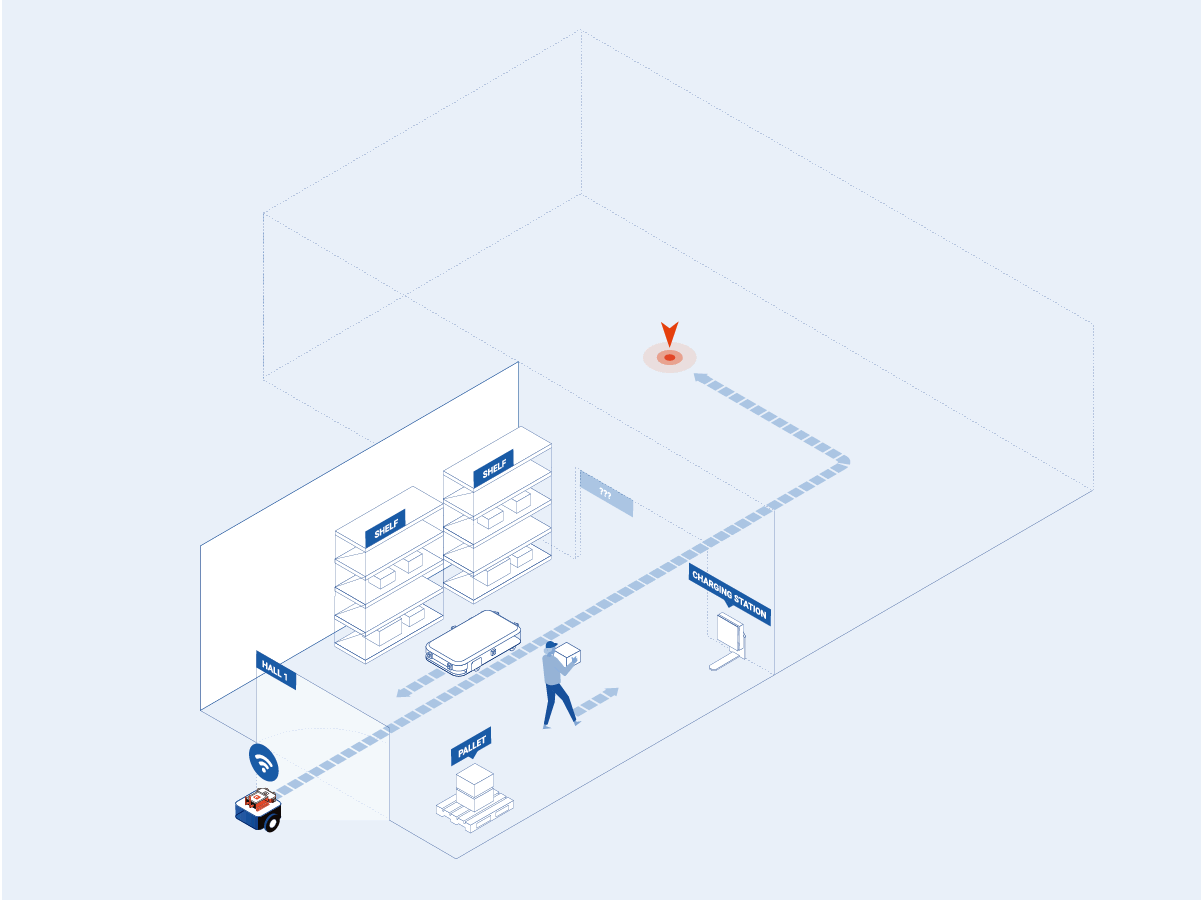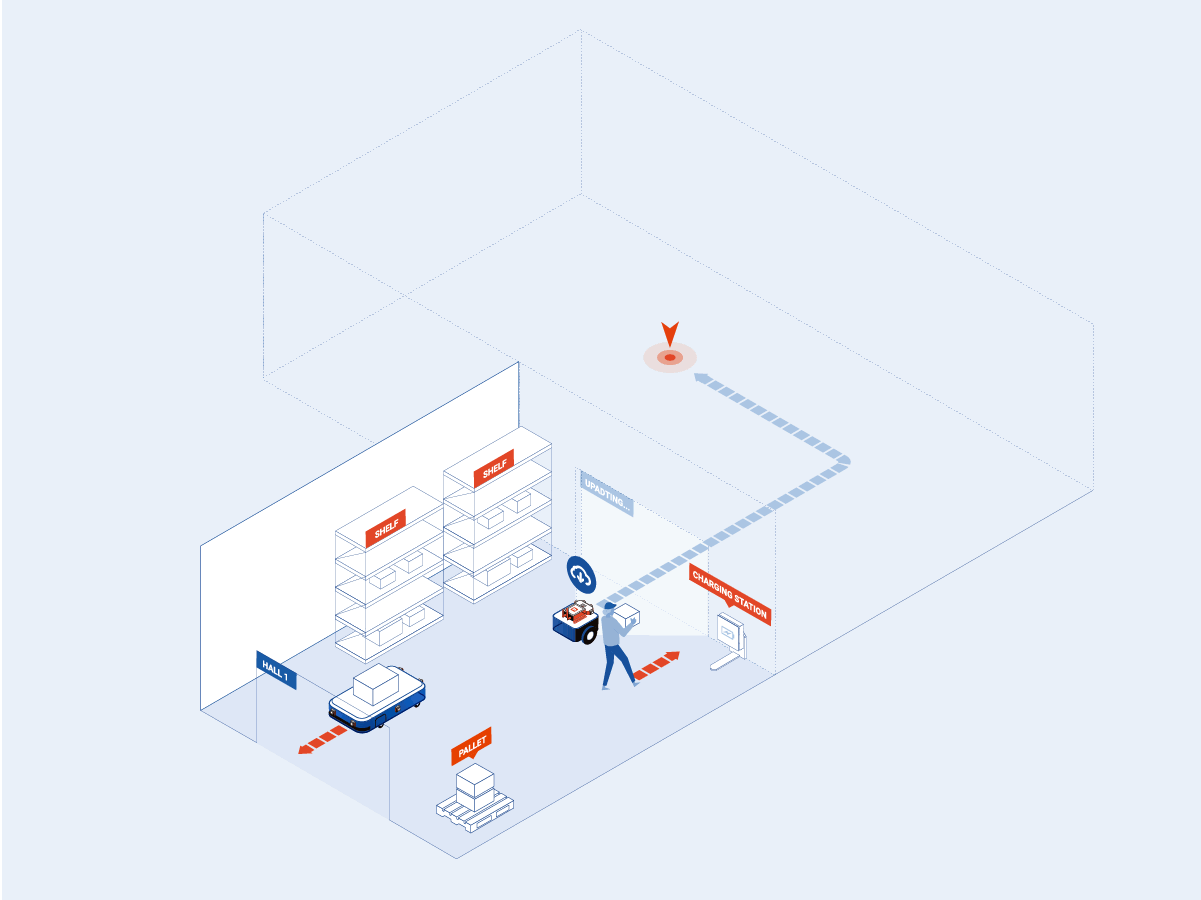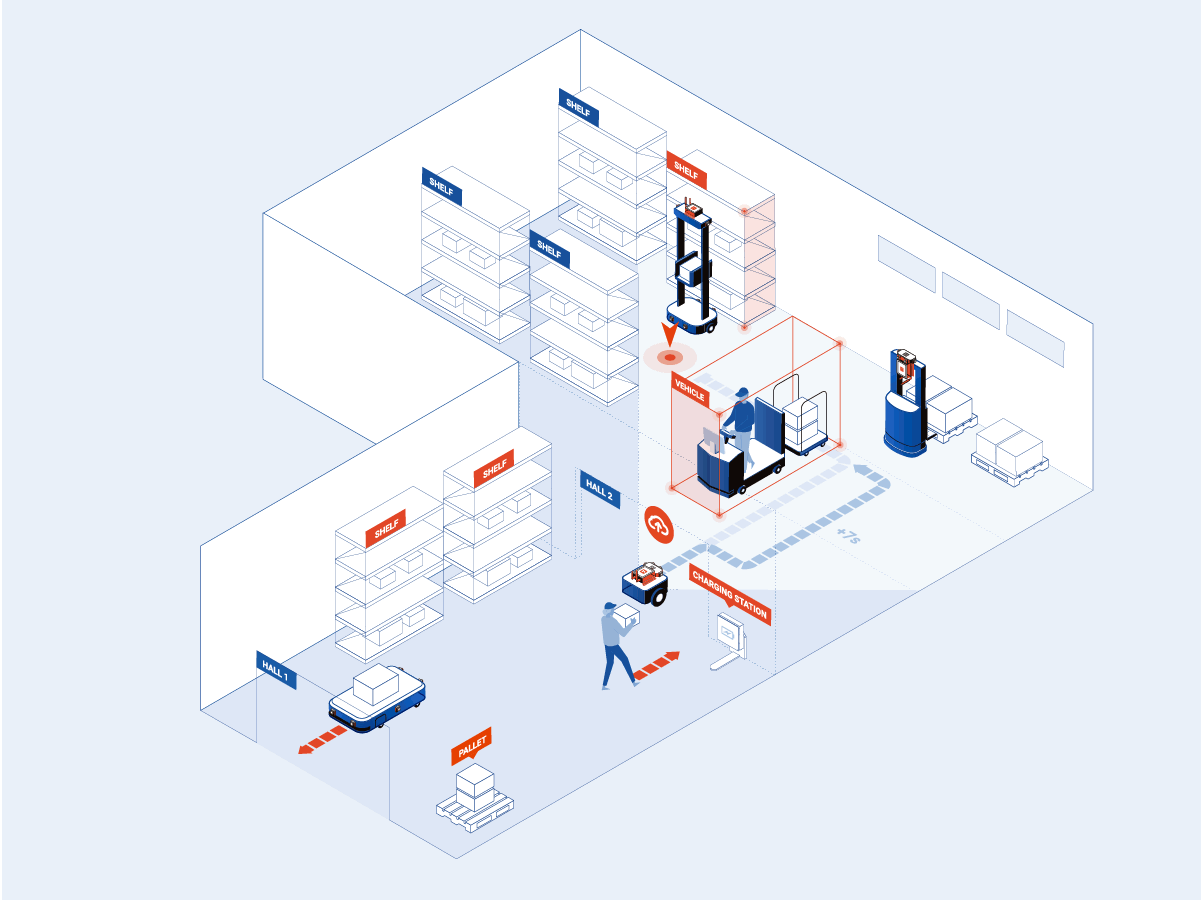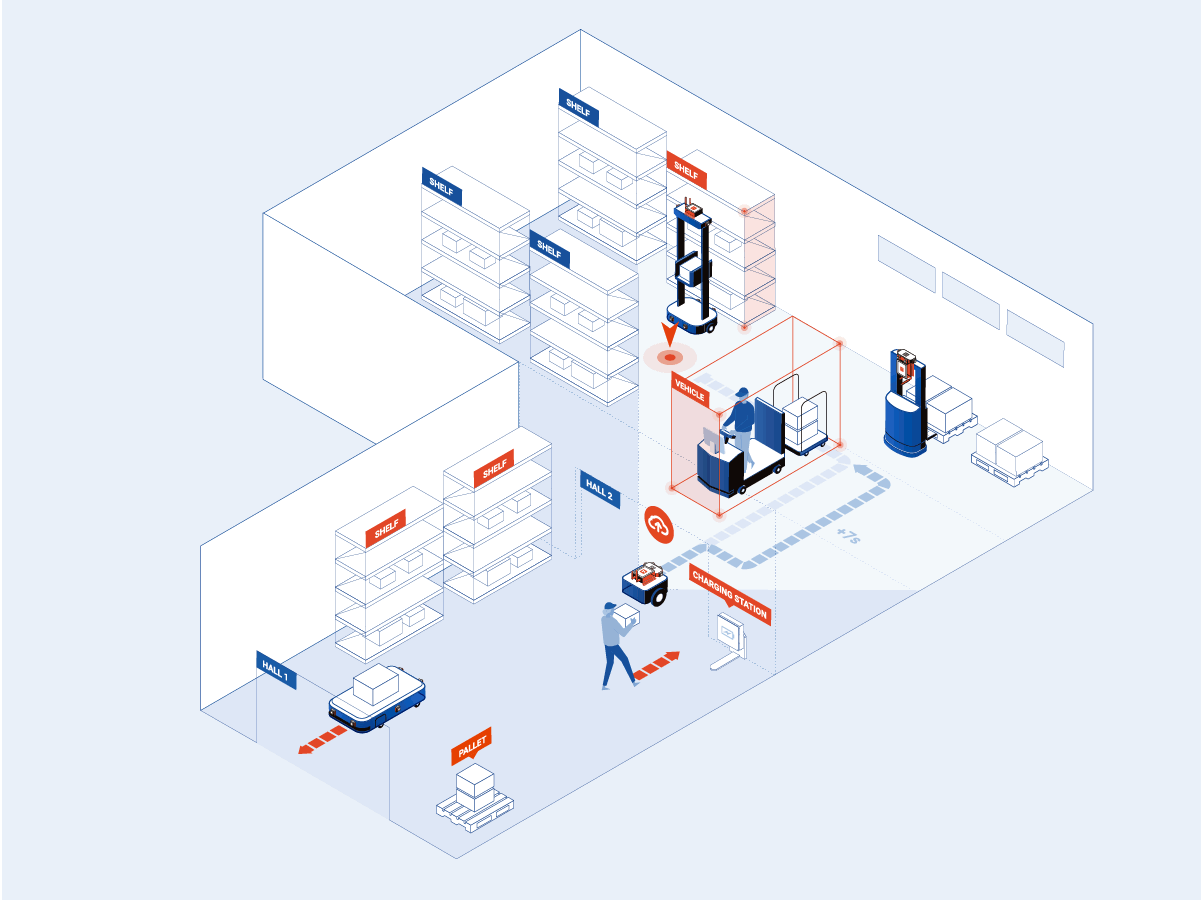
The Lifelong Visual SLAM solution enables building and maintaining always-up-to-date maps. These maps incorporate data from multiple conditions of the environment, such as during cloudy- and sunny weather, bright and dark lighting situations, and changes in the elements present in the area, e.g. changes in factory floor layouts, or simply in the warehouse or shop inventory. All of these changes are detected automatically and incorporated into the lifelong map.
This allows the maps to be used for visual positioning in environments that change considerably over time.
To enable autonomous navigation even in complex and ambiguous environments, a Convolutional Neural Network is employed to perform Semantic Scene Understanding making it possible to detect, classify, determine the position, -and when applicable, predict the movement of obstacles e.g. people and vehicles, and other objects of interest such as pallets, trolleys, floor markings, docking or charging stations.
After the robots have gained insights into their environment and the expected behavior of the elements around them, it is time for them to plan their next move. Reinforcement Learning makes it possible for robots to adapt their navigation behavior -stopping, slowing down, or overtaking obstacles, based on real-time perception, allowing them to interact with the environment, for example, docking, picking, or charging, while safely sharing the floor with moving elements like people and other vehicles.
All of these processes happen on the Edge, on the multi-camera Alphasense Edge AI device -a GPU-accelerated compute unit- embedded in the robot. By bringing computational power closer to the data source, Sevensense minimizes latency challenges -enabling nearly simultaneous, real-time perception and decision-making- and addresses security and privacy issues typically present in solutions purely based on cloud computing, where visual data needs to be recorded and transmitted to remote servers for processing.
Sevensense Visual AI in Action
AI-Powered Continuous Performance Improvement
To exceed the ever-increasing performance requirements of the market, both in terms of accuracy and robustness, Sevensense leverages ongoing cutting-edge developments in the fields of AI, computer vision, and robotics.
Sevensense uses AI models to enrich Sevensense’s simulation, training, and testing infrastructure.
Combining Generative AI and Digital Twins, Sevensense is able to create the most challenging training and testing environments to continuously validate its software stack and ensure it continues to deliver the best-in-class performance and robustness it is known for.
Visual AI Analytics
The visual data captured by the cameras, apart from providing inputs for best-in-class localization and autonomy performance, also unlocks the potential for providing ground-breaking additional services.
The rich visual data captured by the cameras allows Sevensense to offer further Visual AI analytic services focused on providing organized data and insights -beyond Visual SLAM- such as asset tracking, stocktaking, surveillance, and inspection, as an additional safety or reporting data layer.
Do you want to learn more about our Visual AI technology? Get in touch!





'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices

